

Ah se na época da faculdade eu tivesse esse conhecimento para me auxiliar em minhas leituras, com certeza seria tua muito mais fácil. 😅
Brincadeiras a parte, com as diversas responsabilidades que temos durante o dia, tempo é uma coisa cada vez mais rara para as pessoas e se tivermos ferramentas que nos ajudam a otimizar nossas atividades diárias temos que, pelo menos, avaliá-las.
Neste artigo vamos trabalhar com uma das formas de resumir textos da internet. Existem duas maneiras de trabalharmos com resumos de textos: Processamento de Linguagem Natural (PLN) e Deep Learing.
Neste artigo vamos trabalhar com resumos gerados a partir do algoritmo básico de Processamento de Linguagem Natural.
Cadastre-se
Se cadastre no Space Data e tenha acesso a todo o conteúdo exclusivo para membros. É gratuito e sempre será!
Bibliotecas utilizadas
- nltk → Processamento de Linguagem Natural (PLN);
- string → Trabalharmos com string, especificamente com as pontuações;
- heapq → Trabalharmos com priorização;
- IPython.core.display → Trabalharmos com HTML;
- goose3 → Para extrairmos textos de páginas da internet.
Passo-a-passo
Abaixo está o passo-a-passo para facilitar o entendimento de todo o processo:
- Pré-processamento do texto;
- Remover excessos de espaços
- Remover stopwords
- Remover pontuação
- Concatenar em um único parágrafo
- Frequência das palavras;
- Frequência proporcional das palavras;
- Tokenização das sentenças;
- Notas para as sentenças;
- Ordenação das melhores sentenças;
- geração do resumo.
Visualize no Google Colab
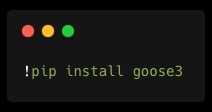
A primeira coisa que precisamos fazer é obter os dados para resumirmos. Nesse caso, vamos usar a biblioteca goose3 que vai nos ajudar a obter dados da internet. Vamos começar instalando a biblioteca no Colab:
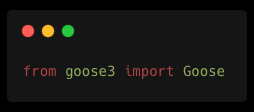
Feita a instalação da biblioteca, vamos agora importar todas as bibliotecas que utilizaremos neste primeiro momento:
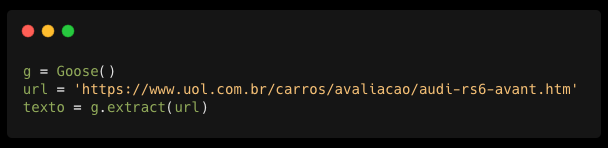
Chegou a hora de obtermos os dados do site do nosso interesse. Fique a vontade para usar qualquer site que queira.
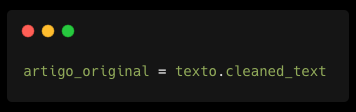
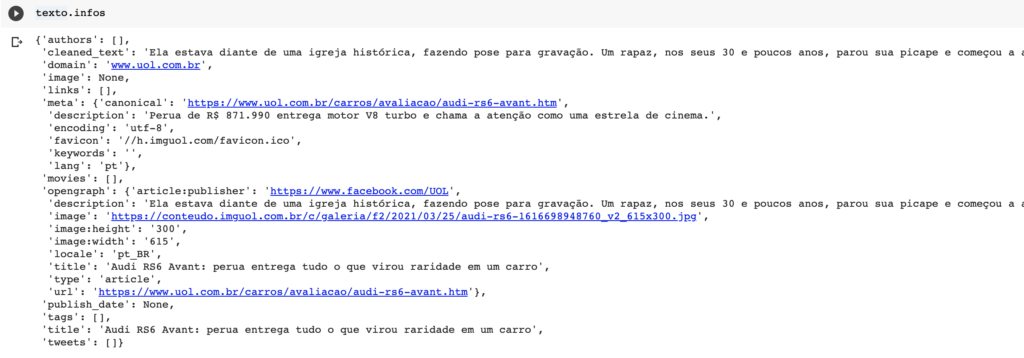
Vamos agora criar uma variável chamada texto_original e atribuir o valor de texto.cleaned_text.
O cleaned_text é um dos atributos contidos no conteúdo que o g.extract(url) nos retorna. Neste atributo está todo o conteúdo do texto, já com todas as tags HTML excluídas, ou seja, temos somente o texto limpo para trabalharmos e partirmos para o próximo passo, o pré-processamento do texto.
Para você ter acesso ao conteúdo completo, basta rodar um texto.infos para acessá-lo. Faça alguns testes e retorne outros conteúdos selecionando o atributo que deseja, como por exemplo, texto.title vai nos retornar o título do texto e assim por diante.
Pré-processamento do texto
Na fase de pré-processamento do texto teremos que excluir os stopwords e as pontuações de todo o nosso conteúdo. Para isso, precisamos importar algumas bibliotecas que nos ajudarão nesse processo:
Stopwords são aquelas palavras que não dão tanto significado para a sentença, ou seja, elas podem ser ignoradas e mesmo assim a sentença consegue manter o seu significado. Alguns exemplos: as, e, os, de, para, com, sem…
Logo abaixo você consegue acessar todas as stopwords que a biblioteca nltk considera para o português.
Saiba mais aqui


Assim que importarmos as bibliotecas, precisamos obter os stopwords e as pontuações para retirarmos do nosso texto:

Assim que importarmos as bibliotecas, precisamos obter os stopwords e as pontuações para retirarmos do nosso texto:



Vamos criar a função para tratar o nosso texto e deixá-lo prontinho para a próxima fase, ok?
Essa função terá o papel de receber o texto “cru”, ou seja, com as stopword, com letras maiúsculas e pontuações e nos retornar o texto todo tratado, com todas as letras minúsculas (ex.: Antes e antes são consideradas diferentes), sem as stopwords e sem as pontuações.
.

Frequência de palavras
Nesta fase, vamos precisar pegar todo o artigo pré-processado, extrair cada palavra e contabilizar a frequência que cada uma aparece em todo o nosso texto analisado. Para fazermos este cálculo é super simples, podemos utilizar a própria biblioteca nltk. Vamos então criar uma variável, que vamos charm de frequencia_palavras e atribuirmos o nltk.FreqDist(nltk.word_tokenize(texto_formatado)). veja:

Isso nos retornará a quantidade que cada palavra aparece no nosso texto, algo mais ou menos assim:

Agora vamos para a próxima fase, que é o cálculo da frequência proporcional de cada palavra!
Frequência proporcional
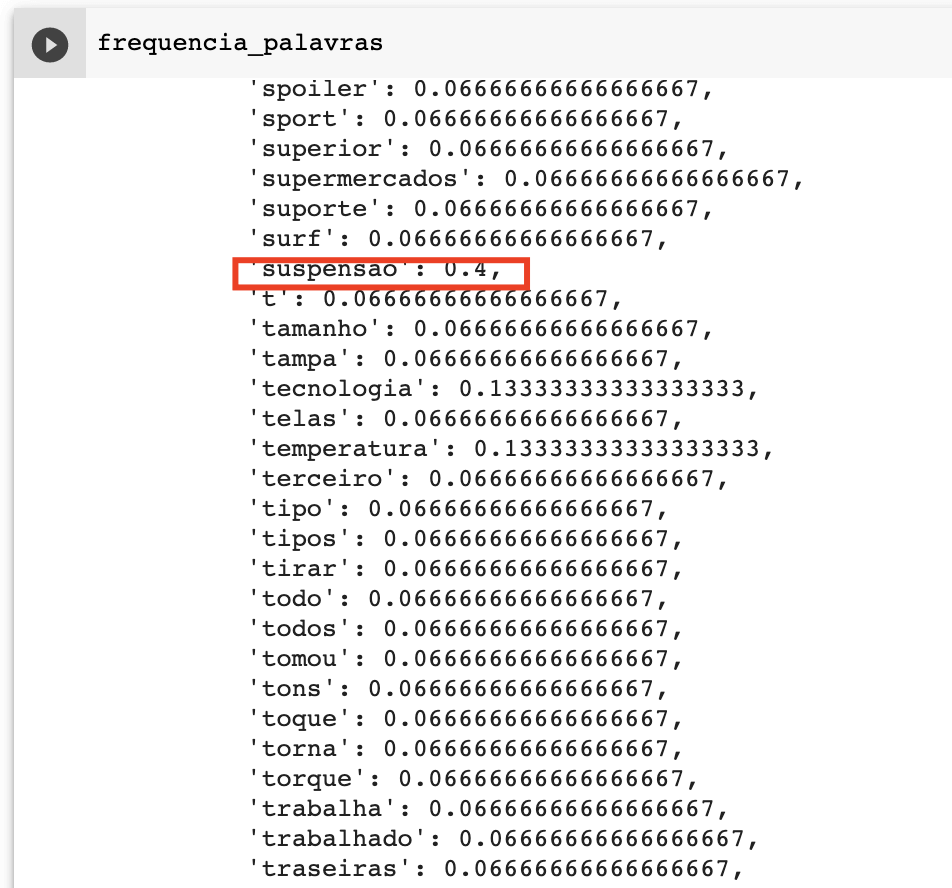
A frequência proporcional consiste em pegar o total que cada palavra aparece no nosso texto e dividir pelo número da palavra com maior frequência no nosso texto. Por exemplo: No nosso texto a maior frequência foi 15. Assim, a palavra suspensão que apareceu 6 vezes, terá uma frequência de 0.4 (cálculo simples aqui: 6 / 15 ). E para chegarmos nesse valor, vamos utilizar um for. Vamos ver?

Tokenização das sentenças
O processo de tokenização das sentenças consiste em pegar o texto original completo e separar cada uma das sentenças, ou seja, vamos separar as frases a cada ponto final. Aí você me pergunta, e palavras abreviadas, como Prof., Dr., Etc.? Todos estes exemplos terminam com um ponto final e na teoria deveria quebrar o texto, certo? Bem, como estamos utilizando uma biblioteca de Processamento de Linguagem Natural, não temos este problema, pois ela já faz essa distinção pra nós. Muito bom, né?
Então vamos a implementação!


Notas para as sentenças
Agora que temos o valor de cada palavra, o que faremos é dar uma nota para cada uma das frases separadas no passo anterior. Dessa forma, o nosso resumo será gerado com as frases de maior nota, ou seja, a soma de cada uma das palavras.
Para isso, vamos criar uma função:

Agora se visualizarmos a variável nota_frases teremos a nota que cada frase recebeu de acordo com a soma dos valores da frequência proporcional de cada uma de suas palavras. São justamente as frases com maiores notas que irão compor o nosso resumo.

Ordenação das melhores frases
Para ordenarmos as sentenças de acordo com as suas notas, vamos utilizar mais uma biblioteca que tornará essa tarefa muito simples, vamos importar a biblioteca chamada heapq.

Assim que importarmos precisamos criar uma variável e atribuir o número de melhores frases (aquelas com maiores notas). A quantidade de frases que queremos retornar deve ser informada no primeiro parâmetro do heapq.nlargest, neste caso, como temos um número relativamente grande de frases, vamos selecionar 10 frases.


Veja aqui as nossas melhores frases que irá compor o nosso resumo. Estamos no final do nosso processo para resumir o nosso texto. O que precisamos agora é concatenar as frases e visualizar o nosso resumo melhor formatado.
Gerando o resumo


Visualizando o resumo em HTML
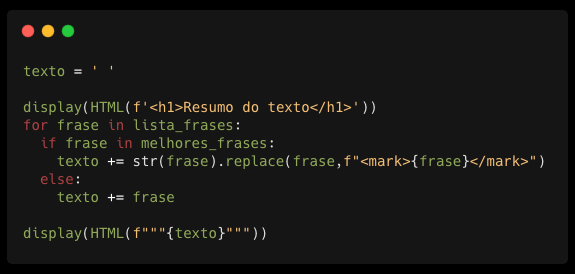
Para deixarmos o nosso resumo mais visual, vamos utilizar a biblioteca IPython.core.display. Se você têm um conhecimento básico de HTM não vai encontrar grandes dificuldades nessa parte.
Está aí o resultado do nosso resumo!

Acho que 10 frases não é o suficiente, né? Vamos aumentar a quantidade para 20 e rodar novamente.

Considerações finais
Este processo de resumo de texto é um dos mais simples, mas em muitos casos pode ser de grande ajuda. Façam o teste com outros textos, leiam o texto completo e o resumo em seguida e vejam se com o resumo é possível entender o conteúdo sem grandes perdas de informação. Em breve postarei outras formas de resumo de texto um pouco mais complexas e com resultados melhores, talvez.
Deixem nos comentários o que achou do conteúdo. Críticas construtivas são sempre bem recebidas por aqui 😉
Espero quem tenham gostado do conteúdo e qualquer dúvida é só deixar nos comentários também que estaremos sempre prontos a ajudar.





You must be logged in to post a comment.