















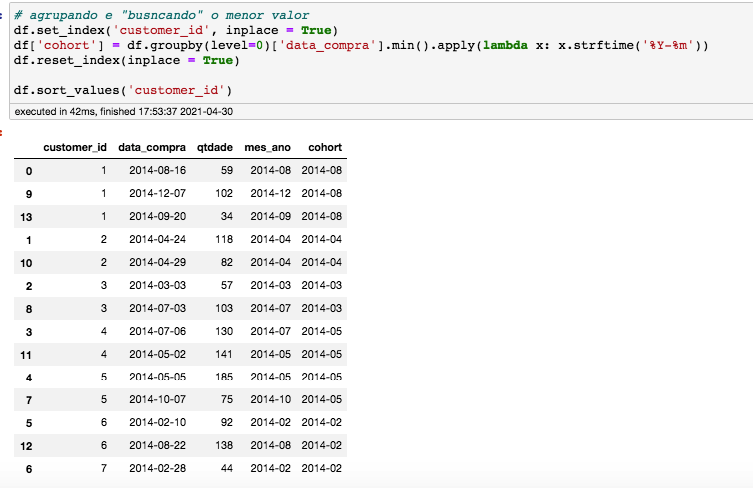

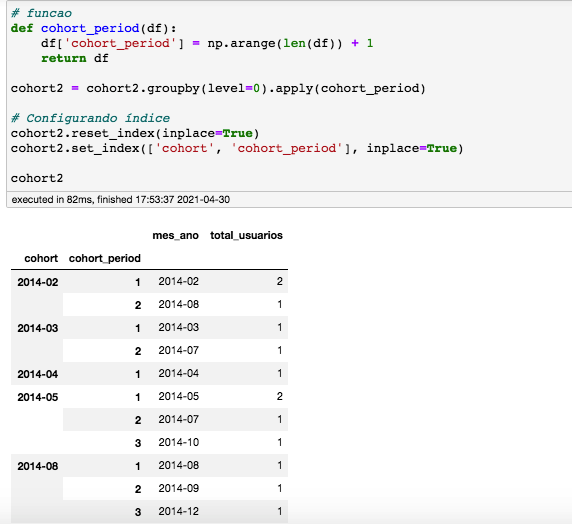










No livro Lean Analytics, foi dedicado um capítulo inteiro sobre as características de uma boa métrica.
O livro é realmente muito bom, cheio de conteúdo e exemplos. Se quiser saber mais, você pode consulta-lo no site da Amazon, clicando aqui: Lean Analytics: Use Data to Build a Better Startup Faster
Obs: Até onde encontrei, foi publicado somente na versão em inglês.  Não é um livro de difícil entendimento, mas você precisa ter uma noção razoável do idioma para compreender.
Não é um livro de difícil entendimento, mas você precisa ter uma noção razoável do idioma para compreender.
Métricas – O que é uma boa métrica?
Estamos em contato com indicadores e índices o tempo todo, mas será que todos estes números realmente fazem sentido e direcionam nossas ações para os resultados?
 )
)Métricas Qualitativas e Quantitativas
Imagine que você está fazendo uma análise de respostas dadas por determinados clientes, chegando nas métricas:
Como você definiria cada um destes conceitos? O que você consideraria como “Bom” estaria no mesmo nível de satisfação que os demais clientes?
Este é um exemplo de métrica qualitativa. Além de ser imprecisa, é difícil de agregar e comparar, além de bastante subjetiva.
Já as métricas quantitativas, como pontuações e taxas são fáceis de contar, colocar em uma escala e quantificar.
Quantidade de produtos devolvidos em relação ao total de produtos vendidos é uma boa métrica quantitativa.
Consegue notar a diferença? Deixe aqui nos comentários ⬇
Métricas Reais e Métricas de Vaidade
Esta é uma das características de boas métricas citadas no livro que eu mais gostei, pois me identifiquei muito com o que já vi muito dentro das organizações.
Uma frase, inclusive, citada no livro, me chamou bastante a atenção:














Somos uma comunidade focada em aproximar pessoas que buscam compartilhar conhecimentos em dados!