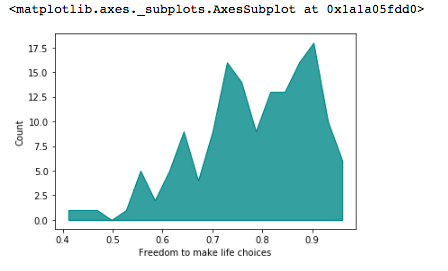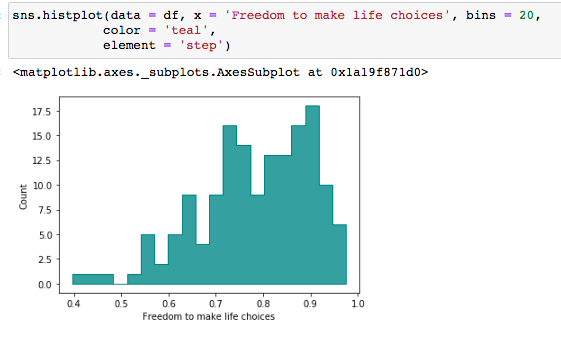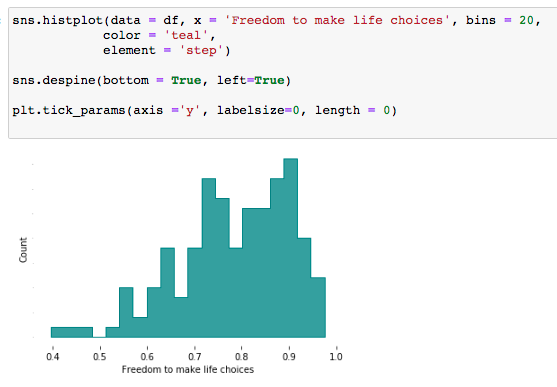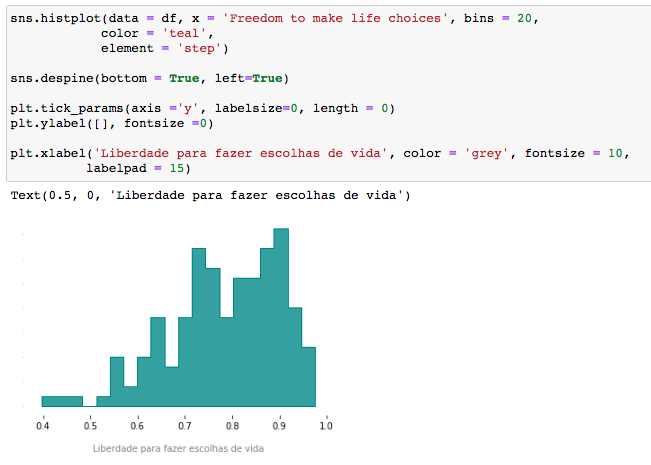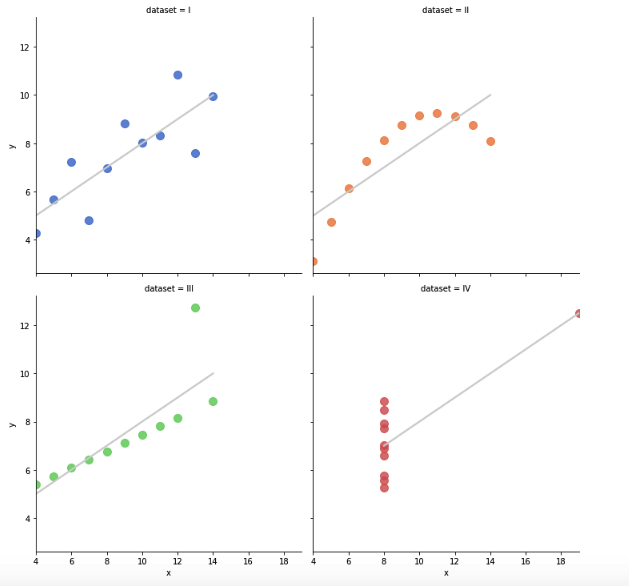














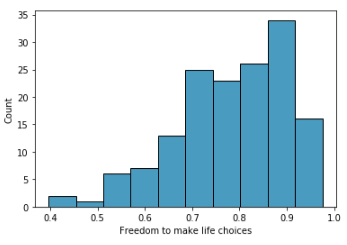
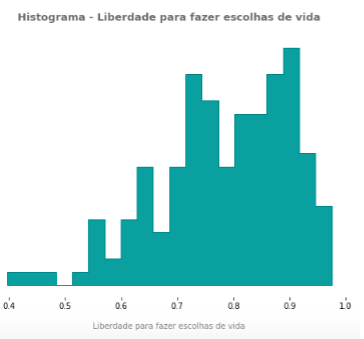
Este plot está com as configurações default da biblioteca Seaborn. Note que só informamos o dataset e o eixo x.


Somos uma comunidade focada em aproximar pessoas que buscam compartilhar conhecimentos em dados!