




Com esta segmentação, o entendimento do que está acontecendo fica muito mais fácil.
No eixo X, temos a quantidade de períodos analisados. No eixo Y, os meses e os percentuais de engajamento ao longo dos períodos (se você ainda está confuso(a), calma, ficará mais claro ao longo deste artigo).
Tomando como exemplo o mês 01/2011 (o primeiro do nosso gráfico), de 100% de usuários que engajaram no primeiro período, apenas 37% continuaram engajados no segundo período.
Neste contexto, um número interessante é o mês 10/2011. Por que somente 7% se manteve engajado?
Com este exemplo, acredito (e espero) que tenha conseguido deixar bem claro como a análise de Cohort é útil.
E como fazer a análise de Cohort ou Coorte em Python?
Não é difícil, mas pode um pouco chato de entender a lógica. Então, vamos fazer com dois dataset’s bem simples, passo-a-passo e depois aplicamos os métodos em um dataset do Kaggle. 



Agora, fica um pouco chato para entender a lógica ( ), mas é fácil, juro.
), mas é fácil, juro.
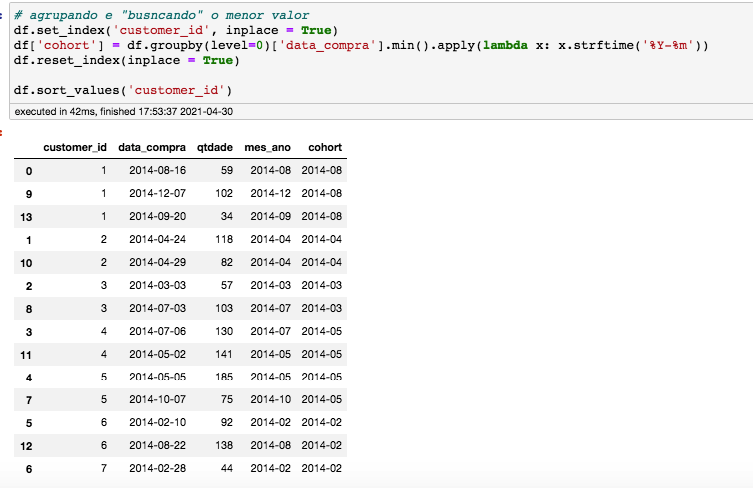
Lembra que a coluna “cohort” contém a menor data de cada cliente, certo? No caso, a data da primeira compra de cada cliente.
A coluna “mes_ano” contém os mês e ano que os clientes fizeram compra (independente se foi a primeira, segunda, terceira, etc., compra).
A coluna “total_usuarios” irá armazenar a quantidade de clientes.
Considere o primeiro grupo, de 2014-02: Há dois clientes que realizaram a primeira compra em 02/2014 (coluna cohort) e destes 2 clientes, 1 comprou também em 08/2014.

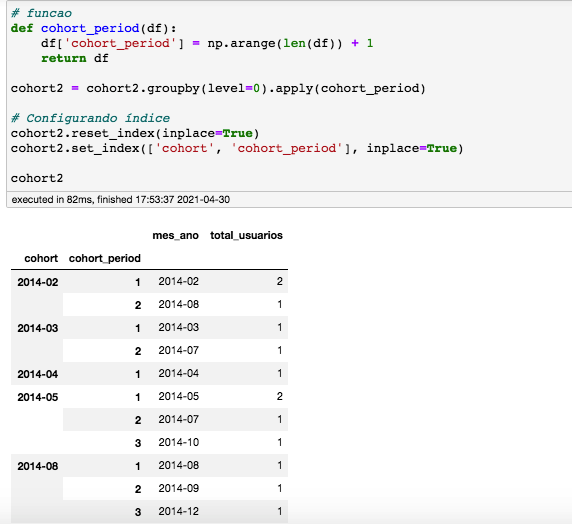

Com a função “unstack”, vamos “pivotar” (este verbo existe?  ) nosso DataFrame.
) nosso DataFrame.
Note que os meses viraram colunas e a coluna “cohort_period” se transformaram em índices:

Por fim (e o mais esperado  ), vamos plotar o heatmap – e interpretá-lo.
), vamos plotar o heatmap – e interpretá-lo.
Veja que os índices estão, agora, no nosso eixo X. O primeiro período,no caso, o 1 será 100% pois estamos considerando o total de clientes que fizeram sua primeira compra no mês em questão, ou seja, o mês que se encontra no eixo Y.
Ao longo dos demais períodos, notamos queda:

Se você não entendeu 100% nossa lógica, vamos visualizar novamente aquela etapa que agrupamos pelas datas (se não lembra de quando fizemos isso, volte três prints  ).
).
Veja que tivemos duas vendas ocorridas pela primeira vez em 02-2014 e uma delas (50%) comprou também em 08-2014.
Agora compare com o Heatmap que fizemos. É exatamente isso que nos mostra.
O mesmo acontece com o mês 05-2014. Foram quatro vendas feitas, cuja primeira data foi no mês de maio/14 ( 2+ 1 + 1 na coluna “total_usuarios”), sendo que houve recorrência de 1 em 07-2014 e outra em 10-2014 (50% e 50%).

Veja que é bem parecido com o dataset anterior, a diferença é que este contém um pouco mais de dados, mais especificamente, mais linhas.
Sugiro comparar os dados e o Heatmap. O entendimento ficará muito mais claro 

O Cohort ou Coorte destes dados, resulta nesse gráfico aqui abaixo 
Veja que temos 6 vendas em 05/2014 dos clientes com ID 04 e 05. Este é um cohort.
Olhando somente este grupo, houve, portanto, compras em 05/2014, 07/2014, 10/2014 e 11/2014.
Com isso em mente, olhe nosso Heatmap. No mês 05/2014, temos
- 100% no período 01.
- 50% no período 02 = Compra da linha 07.
- 50% no período 03 = Compra da linha 10 e 11 (note que estamos falando do mesmo cliente, logo, temos 50%)
- 50% no período 4 = Compra na linha 12.


E o que podemos tirar desta visualização?
Como falamos ao longo deste artigo, temos a abertura por mês de cada um dos grupos, ou de cada cohort, e com isso, imaginando que esta fosse uma situação real em nossas empresas:
- Vemos que o percentual, na maioria dos meses, cai entre 75% – 80% do primeiro mês ao segundo, com exceção do grupo de 10/2011. O que ocorreu para que o percentual ficasse tão abaixo dos demais grupos?
- Esta mesma situação ocorre em 08/2011, quando a terceira interação (pode ser venda, engajamento, uso do seu APP / serviço, etc.). Vemos que caiu praticamente metade em relação aos demais meses.
- Ainda há números não tão discrepantes, mas ainda assim para ficarmos atentos: Começamos o ano com uma taxa de 41% de interação. Vemos que esta taxa foi caindo ao longo dos meses.
Vemos que caso os números estivessem agrupados, seria impossível termos este tipo de visão.
A análise de Cohort nos permite visualizar padrões durante o ciclo de vida de nossos clientes. Lembrando que esta visualização pode ser feita para receita, churn, custos e muitas outras métricas do seu negócio.
Espero que possa te ajudar em suas análises. 
Qualquer comentário, pode deixar aqui abaixo 
Entender esta análise, além da sua aplicação em Python, levou alguns dias estudando
Vou deixar alguns links que me ajudaram muito no entendimento deste conceito (em inglês):
 Youtube
Youtube
Retention and Cohort Analysis with Bei Lu (Youtube)
Cohort Analysis: An introduction Whiteboard Wednesday
 Artigos
Artigos





You must be logged in to post a comment.