

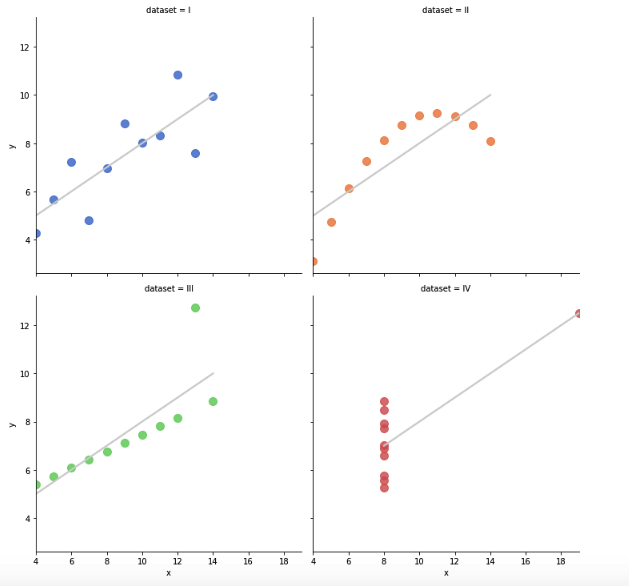



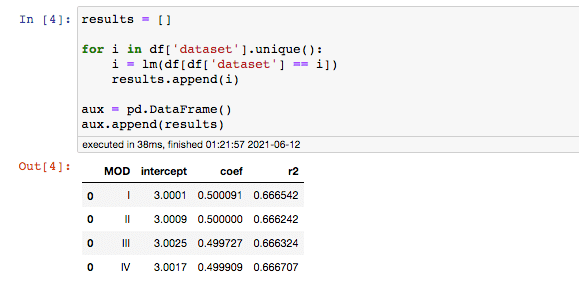

O termo Data Science já não é mais novidade para ninguém. A…

O que é Análise de Cohort (coorte) e como aplicá-la em Python…

Métricas e Indicadores de Desempenho Um artigo segundo o livro Lean Analytics…

Somos uma comunidade focada em aproximar pessoas que buscam compartilhar conhecimentos em dados!
You must be logged in to post a comment.