

O que é Análise de Cohort (coorte) e como aplicá-la em Python

Este é o segundo post da série de artigos referente ao livro Lean Analytics.
Você pode conferir o primeiro post aqui: https://spacedata.com.br/indicadores-de-desempenho/
Se você quiser conferir o livro no site da Amazon, só clicar aqui: Lean Analytics: Use Data to Build a Better Startup Faster
O que é Análise de Cohort ou Coorte?
O conceito não é nada complicado: é a análise onde se compara grupos com características semelhantes e os monitora durante um período específico.
Pode ser idade, data da compra, região, data de cadastro, etc. Geralmente, é considerado o primeiro “contato” deste cliente, como primeira compra, primeiro uso (imagine um serviço de carro por aplicativo ou de comida delivery) e então, você monitora:
- Desde a primeira compra, este grupo de clientes voltou a comprar?
- Desde o primeiro pedido de comida delivery, este grupo de clientes voltou a pedir?
- O grupo de clientes que tiveram sua primeira corrida no mês 08/2020 utilizou novamente o serviço nos meses subsequentes? E os que fizeram a primeira corrida em 09/2020, 10/2020, etc?
Outro exemplo é a taxa de engajamento:
- Seus usuários estão utilizando sua plataforma todos os dias?
- Qual o percentual de usuários que voltam no dia seguinte ao cadastro? E na semana seguinte? E no mês seguinte?
A análise de Cohort ou também conhecida como Coorte é muito importante para medir o quanto seus clientes/usuários/consumidores são leais a sua marca e a sua empresa. Ao invés de olha-los todos da mesma forma, você os separa conforme suas características.
Para ficar mais claro, vamos a um exemplo mais visual.
Vamos imaginar que estamos medindo o engajamento dos usuários em uma página, perfil, canal, etc. No gráfico de linha abaixo, fica claro para nós que, mesmo com algumas “subidas e descidas”, o nosso engajamento está aumentando ao longo do tempo, mas…

- Quantos usuários são novos?
- Quantos usuários engajados no mês 12/2011 são usuários cadastrados no início do mês?
- Quantos estão engajados há 2 meses? e há 3 meses? 6 meses?
Olhando somente para este gráfico, fica bastante difícil (para não dizer impossível) responder a estas perguntas.
Agora, veja como fica muito mais simples se tivermos uma análise de Cohort:

Com esta segmentação, o entendimento do que está acontecendo fica muito mais fácil.
No eixo X, temos a quantidade de períodos analisados. No eixo Y, os meses e os percentuais de engajamento ao longo dos períodos (se você ainda está confuso(a), calma, ficará mais claro ao longo deste artigo).
Tomando como exemplo o mês 01/2011 (o primeiro do nosso gráfico), de 100% de usuários que engajaram no primeiro período, apenas 37% continuaram engajados no segundo período.
Neste contexto, um número interessante é o mês 10/2011. Por que somente 7% se manteve engajado?
Com este exemplo, acredito (e espero) que tenha conseguido deixar bem claro como a análise de Cohort é útil.
E como fazer a análise de Cohort ou Coorte em Python?
Não é difícil, mas pode um pouco chato de entender a lógica. Então, vamos fazer com dois dataset’s bem simples, passo-a-passo e depois aplicamos os métodos em um dataset do Kaggle. 🤓
Conheça mais sobre métricas de negócios. Leia o artigo Métricas e indicadores de desempenho
Análise de Cohort - Dataset I
Agora, vamos usar a função em nosso Anscombe’s dataset, armazenar cada um dos resultados e compará-los:
Para ficar bem claro cada uma das etapas até chegar no heatmap final, vamos utilizar dados bem simples.
Nele, há somente três colunas:
- ID do cliente
- Data da compra
- Quantidade comprada
Vamos importar o dataset e para ficar mais fácil a manipulação dos dados, vamos renomear as colunas:

Para os próximos passos, vamos precisar que a coluna “Data da compra” esteja no formato correto, no caso, datatetime.
Esta nova coluna será nomeada com “mes_ano”. Veja que ela deriva da coluna “data_compra”:

A nossa análise Cohort será feita por mês, então, com a função lambda, vamos extrair o mês e ano da coluna “data_compra”:

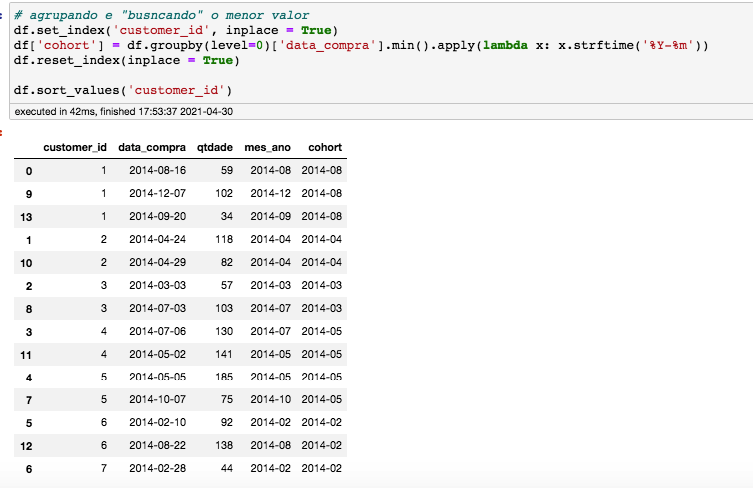
Agora, para cada cliente, vamos buscar a data da sua primeira compra. Esta informação ficará na coluna nomeada “cohort”.
Para ficar mais claro: O cliente de ID 01 fez compras em 08/2014, 09/2014 e 12/2014. Para este cliente, a data na coluna cohort será a menor, no caso, 08/2014 (será repetida em todas as linhas do cliente ID 01).
Para facilitar a visualização, ordenei os dados por ID:
Agora, fica um pouco chato para entender a lógica (😅 ), mas é fácil, juro.
Lembra que a coluna “cohort” contém a menor data de cada cliente, certo? No caso, a data da primeira compra de cada cliente.
A coluna “mes_ano” contém os mês e ano que os clientes fizeram compra (independente se foi a primeira, segunda, terceira, etc., compra).
A coluna “total_usuarios” irá armazenar a quantidade de clientes.
Considere o primeiro grupo, de 2014-02: Há dois clientes que realizaram a primeira compra em 02/2014 (coluna cohort) e destes 2 clientes, 1 comprou também em 08/2014.

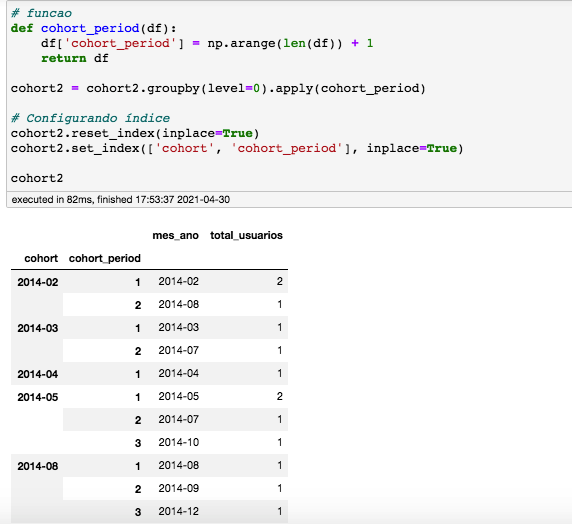
Vamos criar uma função que irá contar a quantidade de períodos em cada grupo “cohort”.
Olhe a coluna cohort 2014-02. Temos 2 compras em em fev/2014 + 1 compra em 08/2014. A primeira data será 01. E a segunda (08/2014) será número 02.
Outro exemplo seria a cohort 05-2014. A linha número 01 será ela mesma, ou seja, 05-2014. A linha 02 será a segunda compra e a linha 03, a terceira compra.
Este dataset é bem pequeno, mas em dados maiores, este contador será também maior. Se sua análise for por 12 meses, por exemplo, pode haver 12 contadores para cada grupo.
Agora, vamos agrupar o total de usuários pela coluna “cohort:

Com a função “unstack”, vamos “pivotar” (este verbo existe? 🤔) nosso DataFrame.
Note que os meses viraram colunas e a coluna “cohort_period” se transformaram em índices:

Por fim (e o mais esperado 🙌), vamos plotar o heatmap – e interpretá-lo.
Veja que os índices estão, agora, no nosso eixo X. O primeiro período,no caso, o 1 será 100% pois estamos considerando o total de clientes que fizeram sua primeira compra no mês em questão, ou seja, o mês que se encontra no eixo Y.
Ao longo dos demais períodos, notamos queda:

Se você não entendeu 100% nossa lógica, vamos visualizar novamente aquela etapa que agrupamos pelas datas (se não lembra de quando fizemos isso, volte três prints 🙃 ).
Veja que tivemos duas vendas ocorridas pela primeira vez em 02-2014 e uma delas (50%) comprou também em 08-2014.
Agora compare com o Heatmap que fizemos. É exatamente isso que nos mostra.
O mesmo acontece com o mês 05-2014. Foram quatro vendas feitas, cuja primeira data foi no mês de maio/14 ( 2+ 1 + 1 na coluna “total_usuarios”), sendo que houve recorrência de 1 em 07-2014 e outra em 10-2014 (50% e 50%).

Análise de Cohort - Dataset II
Caso ainda não tenha ficado tão claro, vamos fazer novamente esta segmentação com o dataset um pouco maior.
Não vou copiar cada um dos snippets aqui porque os métodos são os mesmos, mudei apenas o dataset.
Se você quiser conferir o notebook inteiro, dê uma olhada no Github:
Cohort Analysis
Clique aqui para acessar o notebook no GitHub
Veja que é bem parecido com o dataset anterior, a diferença é que este contém um pouco mais de dados, mais especificamente, mais linhas.
Sugiro comparar os dados e o Heatmap. O entendimento ficará muito mais claro 😊

O Cohort ou Coorte destes dados, resulta nesse gráfico aqui abaixo ⬇
Veja que temos 6 vendas em 05/2014 dos clientes com ID 04 e 05. Este é um cohort.
Olhando somente este grupo, houve, portanto, compras em 05/2014, 07/2014, 10/2014 e 11/2014.
Com isso em mente, olhe nosso Heatmap. No mês 05/2014, temos
- 100% no período 01.
- 50% no período 02 = Compra da linha 07.
- 50% no período 03 = Compra da linha 10 e 11 (note que estamos falando do mesmo cliente, logo, temos 50%)
- 50% no período 4 = Compra na linha 12.

Análise de Cohort - Dataset III
Com o passo a passo feito em dois dataset’s, vamos utilizar outros dados: Vendas de uma loja de varejo.
Este dataset está disponível no Kaggle: Super Store Data
Os métodos utilizados são exatamente os que fizemos acima, então, não, irei repeti-los aqui.
Lembrando novamente que o notebook, na íntegra, está disponível no GitHUb: GitHub – Cohort Analysis
Vamos considerar, nesta análise, somente a data de compra e o ID do cliente:

O resultado será o seguinte Heatmap:
E o que podemos tirar desta visualização?
Como falamos ao longo deste artigo, temos a abertura por mês de cada um dos grupos, ou de cada cohort, e com isso, imaginando que esta fosse uma situação real em nossas empresas:
- Vemos que o percentual, na maioria dos meses, cai entre 75% – 80% do primeiro mês ao segundo, com exceção do grupo de 10/2011. O que ocorreu para que o percentual ficasse tão abaixo dos demais grupos?
- Esta mesma situação ocorre em 08/2011, quando a terceira interação (pode ser venda, engajamento, uso do seu APP / serviço, etc.). Vemos que caiu praticamente metade em relação aos demais meses.
- Ainda há números não tão discrepantes, mas ainda assim para ficarmos atentos: Começamos o ano com uma taxa de 41% de interação. Vemos que esta taxa foi caindo ao longo dos meses.
Vemos que caso os números estivessem agrupados, seria impossível termos este tipo de visão.
A análise de Cohort nos permite visualizar padrões durante o ciclo de vida de nossos clientes. Lembrando que esta visualização pode ser feita para receita, churn, custos e muitas outras métricas do seu negócio.
Espero que possa te ajudar em suas análises. 💕
Qualquer comentário, pode deixar aqui abaixo 👇
Referências
Entender esta análise, além da sua aplicação em Python, levou alguns dias estudando 🤓
Vou deixar alguns links que me ajudaram muito no entendimento deste conceito (em inglês):
🎥 Youtube
Retention and Cohort Analysis with Bei Lu (Youtube)
Cohort Analysis: An introduction Whiteboard Wednesday
📄 Artigos




You must be logged in to post a comment.